
Securing TIER cloud infrastructure with a central IdP
Preface
This post is Part 1 in a series describing the evolution of TIER’s infrastructure stack and tooling landscape. Links to later installments of this series will be added once they are published.
In this first part of the series we’ll cover a bit of history, general principles, and the use of a central Identity provider across our systems.
Please note: this and the following posts are written from the Infrastructure team’s perspective. There are more systems and tooling involved in executing the services and managing their dependencies.
Landscape v1
TIER was launched in late 2018 and has been running on Amazon Web Services since the beginning.
The first service landscape was built on top of serverless.com. This stack gave us an abstraction layer between the cloud provider and the code we wrote as functions. All software stack’s resources were kept in a single GitHub repository including our CI/CD pipelines, Infrastructure, and actual code. We hit several roadblocks along the way, forcing us to change the model.
The pains
On AWS, serverless.com uses CloudFormation as an abstraction layer for managing resources. This comes with all sorts of inherited CloudFormation issues:
- The CloudFormation stacks are auto-generated
- If the stacks fail, it’s difficult to debug and fix.
- We ran into the well-known 200 resources-per-CF-stack issue. This had to be remediated by serverless.com plugins and CloudFormation sub-stacks. If you don’t suspect already - moving resources between (sub)stacks in a production environment is no fun.
- In CI/CD, the stacks take a long time to deploy. Because infrastructure and code are one entity, a change in the code always implies a new CloudFormation deployment.
- Shared resources across teams/software stacks are hard to manage. The solution could be to introduce a layered approach to share networks instead of using self-contained serverless stacks.
Although there is an in-depth analysis of serverless stacks across the different cloud providers focusing on execution costs, one thing we learned, which led to a switch on the operation model, is that serverless is not the best approach if your code is constantly executed.
Landscape v2
In the second version of our infrastructure journey, we decided to go classic and use dedicated flows for code and infrastructure, while also changing the orchestration.
- Infrastructure as Code
Terraform as language of choice.
- This comes naturally as Terraform is a) the de-facto standard in Infrastructure as code (IaC) today and b) has the broadest eco-system support through community and vendor providers.
- separate Infrastructure repository per team
- Infrastructure code managed in CI to allow full auditability. The chosen tool is geopoiesis (self-hosted private tool; the successor is available as SaaS on https://www.spacelift.io/)
- Services
- AWS Elastic Kubernetes Service (EKS) for orchestration
- CircleCI as CI/CD
- HashiCorp Vault for secrets management (this came in with v2.5 of the landscape)
This is how our current landscape looks like today.
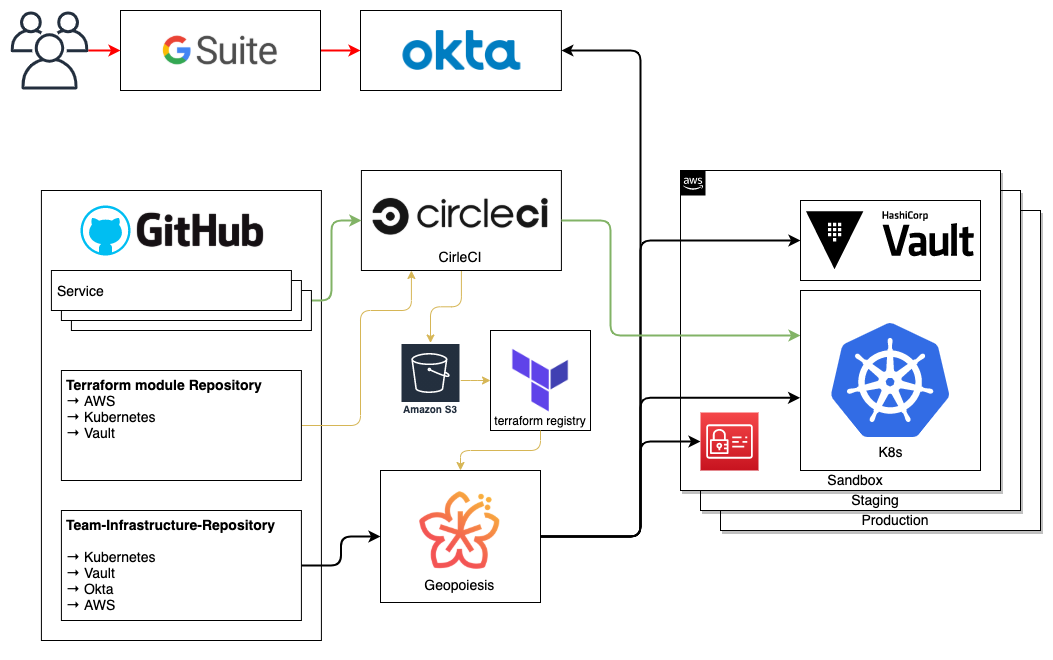
The team as a base for permission management
We structured our permission system around teams – each team manages one or more services, while a service is managed by exactly one team (or so we thought; more on this later in the post series).
There are 3 levels of permissions we manage:
- no permission - No access to the system
- read-only permission - You have read access but cannot modify states
- read-write permission - You’re able to read and also modify states
For each team, this means we have two roles (the no permission is reflected by not applying any of the other two permission sets)
- foo-team-spectator
- foo-team-operator
Mapping humans into the platforms
All of the subsystems in our landscape have their own role-based access control (RBAC) system which we combine with a central Identity provider (IdP).
When managing access for a growing team, you should use a central IDP as a single point of authentication and authorization. It makes on-and off-boarding smoother and easier.
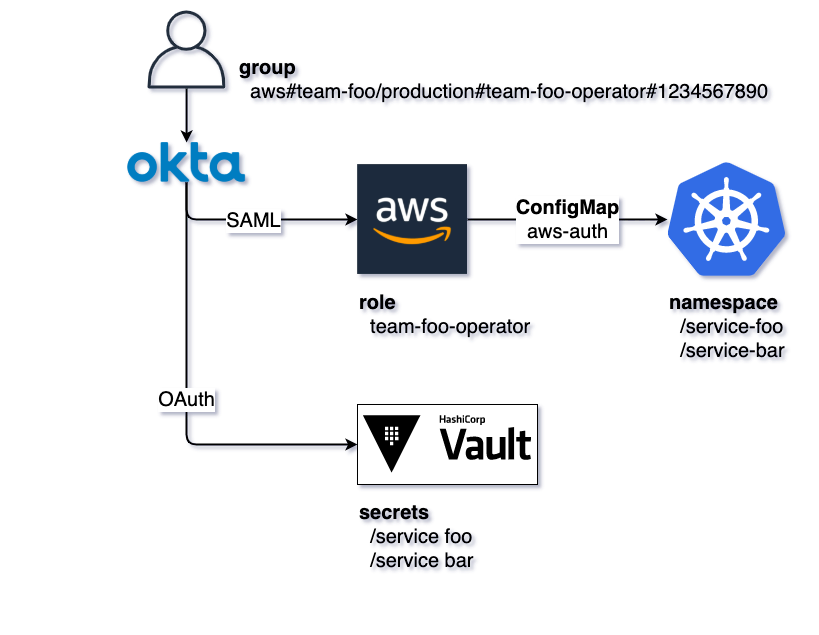
With the central IdP in place and connected to the sub-systems, a human is finally able to:
- Log in to Okta and has groups assigned
- Access Vault (via WebUI or CLI) and has access to certain secrets
- Assume a role in AWS (via WebUI or eg. aws-okta/saml2aws + aws CLI)
- Access EKS via kubectl and has permissions on certain namespaces.
CircleCI is currently relying on GitHub as authentication and authorization backend; GitHub is not yet combined with Okta.
Okta
For each of the teams we create a spectator and an operator group.
aws#<human readable description>#<to be assumed role name>#<AWS account to be accessed>
eg. aws#ring-0/production#team-ring-0-spectator#0123456789
The name has a special meaning for the Okta↔AWS mapping, see below. User management and group assigning in Okta are automated and not part of this post.
Okta ←→ AWS
We do not provide IAM users; we use role assumptions only. The reason is quite simple – no static credentials needed.
AWS role assumption is done via SAML integration, the Okta Groups have a special meaning there
aws#<human readable description>#<to be assumed role name>#<AWS account to be accessed>
See more here
We do not (yet) use SAML attributes but AWS roles have tags and this is a little piece of magic to use single AWS account with different teams:
data "aws_iam_policy_document" "operator_policy" {
statement {
not_actions = [
"iam:*",
“More dangerous actions”,
...
]
resources = ["*"]
effect = "Allow"
condition {
test = "ForAnyValue:StringEquals"
variable = "aws:ResourceTag/Team"
values = [
"$${aws:PrincipalTag/Team}",
"$${aws:PrincipalTag/team}"
]
}
}
The IAM policy translates into - an Operator is allowed to do all actions, which aren’t explicitly forbidden IF the Team-tag on the resources is the same as on the user’s role.
Yes, nothing must be changed manually but allowing to do so in cases of emergency is also nice.
This has some drawbacks, for example, have S3 objects separate tags than the S3 bucket and they are not inherited. The policy also requires to have a very strict tagging system.
👉 The Terraform AWS provider supports default tags from version 3.38 on https://registry.terraform.io/providers/hashicorp/aws/latest/docs#default_tags
AWS ←→ Kubernetes
EKS has a central configuration (aws-auth ConfigMap in kube-system namespace) which maps IAM entities to kubernetes RBAC.
👉 Each service has its own kubernetes namespace for separation. The team’s RBAC entities get permissions granted on these namespaces individually.
Problem is that aws-auth ConfigMap is a single resource, which in our case is created out of many team fragments. To work around this problem, we wrote the aws-auth-operator and open-sourced it.
Native EKS OIDC integration is now possible. Find out more:
- TierMobility/aws-auth-operator
- Managing users or IAM roles for your cluster
- Introducing OIDC identity provider authentication for Amazon EKS
- Authenticating users for your cluster from an OpenID Connect identity provider
Okta ←→ Vault
An easy one – we decided to not go with the native Okta integration (might also not have been available back in the days) and use plain OpenID Connect (OIDC).
The Okta groups are reflected in Vault Identity groups and get, in the end, access to their team’s paths
# Allow managing secrets
path "XXX-team-infra/secret/*" {
capabilities = ["create", "read", "update", "delete", "list"]
}
# Allow listing & reading database credentials
path "XXX-team-infra/database/creds/*" {
capabilities = ["read", "list"]
}
# Allow listing & reading database roles
path "XXX-team-infra/database/roles/*" {
capabilities = ["read", "list"]
}
👉 Use dynamic Database secrets, they rock!
See more:
Okta ←→ XYZ (a conclusion)
Okta is also used for nearly all other systems. As written above - do invest in a central IdP early and save yourself a lot of problems in the long run.
The series
- Building TIER cloud infrastructure as code - Part 1 // Landscape and Centralized Authentication
- Building TIER cloud infrastructure as code - Part 2 // Environments and Team based code
- Building TIER cloud infrastructure as code - Part 3 // TF-CIX as an approach to share information between terraform stacks
{kind=link}

Tips for Optimizing Docker Builds
Building TIER cloud infrastructure as code - Part 2
