
Prefix
Learn why we moved from service infrastructure based on teams to managing service creation and access in a single git commit. Daniel Ciaglia, Director of Engineering at TIER, describes it in the following words: “A service doesn’t need a human; they are only guests in the service-landscape”.
This article is the first of a two-part series describing the new service-based infrastructure at TIER. First, we will focus on the Service Registry – the central git repository that manages teams and services with help of Terraform. In the upcoming post, you will find out how we put our new service infrastructure approach into practice to have better alerting and monitoring.
Problem statement
At TIER, we always believed that our infrastructure should be built around teams. We assumed that dedicated teams who are responsible for owning and maintaining infrastructure services would lead to time-saving transparency through clear ownership. Technically speaking, this approach meant that everything about the infrastructure of a team and its services should be in Terraform templates of a repository belonging to a single team. If you want to find out more about this approach, check out our blog series “Building TIER cloud infrastructure as code”.
But over time, we had to realize that teams are subject to constant change. For example, if two small teams are merged into one, or bigger teams are cut into smaller units. Or imagine a service needs to be suddenly accessible to multiple teams. Or a service changed ownership and is now managed by a different team. It’s obvious that there’s a large number of possible scenarios in which teams are no longer autonomous and need support from the DevOps folks to decompose and migrate Terraform resources to different repositories and state files.
It was time to come up with a solution. Because if teams are stable, our people-based setup works well. But if teams or services fluctuate, it is preferable to go service-centered. And that is exactly what we did.
The Service Registry: two perspectives
Service perspective
First of all, we started with a central repository - the service registry - that holds information about all services. How are they called, in which Kubernetes cluster they are deployed, in which namespace and repository its source and infrastructure code resides. All this information is held in YAML manifests. Have a look at the code snippet below to see what information it contains. And this shouldn’t come as a surprise: the only information missing is team ownership.
service_name: foobar
repository: github.com/TierMobility/foobar
kubernetes_namespace: foobar
kubernetes_cluster: cluster_1
branch: main
terraform_version: "1.0.9"
Snippet 1. An example service YAML manifest
As a next step, Terraform glues all this information together. Our templates read the services YAML manifests and deploy a Terraform pipeline for each service. This pipeline then deploys the infrastructure that belongs to the service. We will discuss later how each service defines its needed infrastructure in a separate repository.
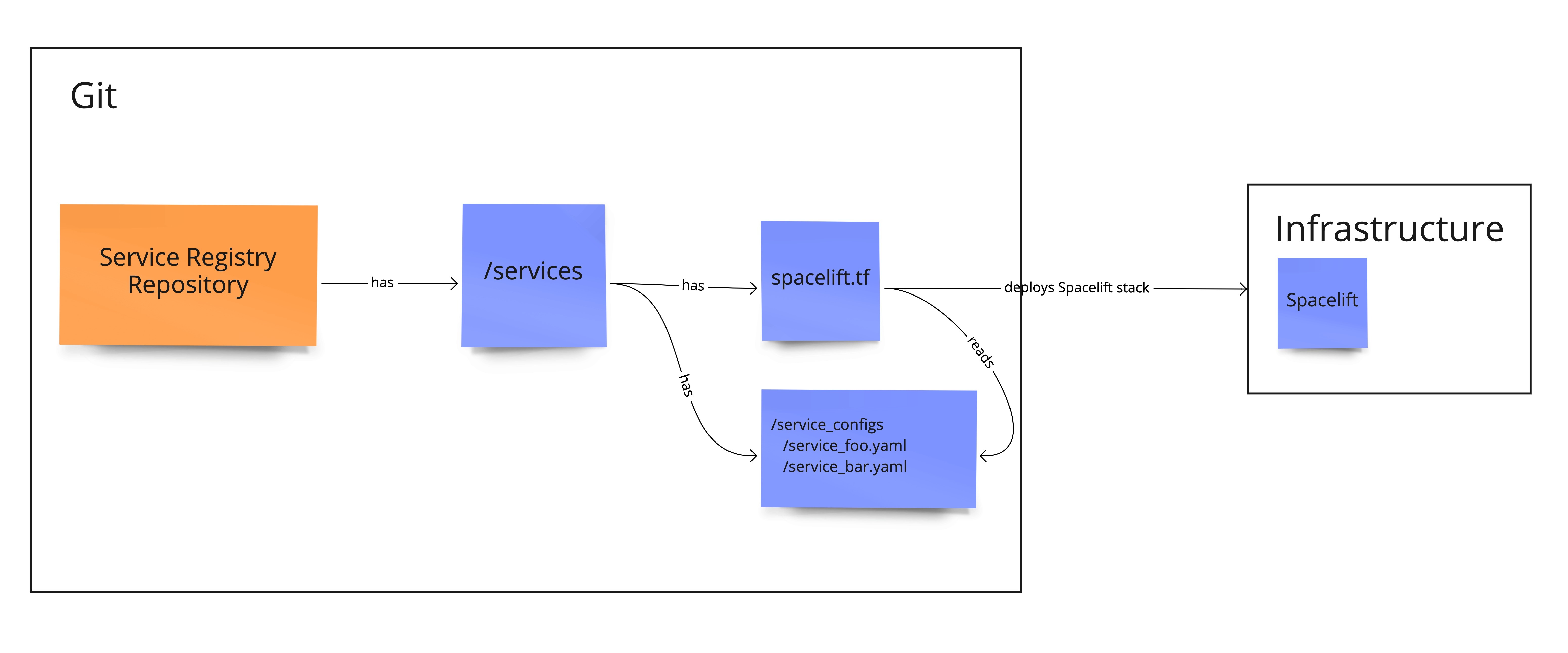
Figure 1. Service perspective
Team perspective
The service registry repository also holds YAML manifests for teams. There we define a team name, a Slack channel belonging to the team and services names it owns or accesses. You can find an example in Snippet 2.
name: my-team
department: my-department
oncall: true
metadata:
slack_team_channel: '#my-team-devops'
slack_team_handle: '@my-team-oncall'
owner:
- example-service
guest:
- example-service-2
- example-service-3
Snippet 2. An example team YAML manifest
Luckily, Spacelift has a feature called Open Policy Agent (OPA) which allows our Terraform templates to read the team YAML manifests and create Okta groups for each team, as well as Vault role, AWS role and Aws Auth Mapping such as shown in Figure 2. For the Aws Auth Mapping, Terraform takes information about services names owned or accessed by the team and fetches more details about each service from the service YAML manifest. It then creates the corresponding mapping in the right cluster and in the right namespace. A diagram reflecting the complete process is shown in Figure 3.
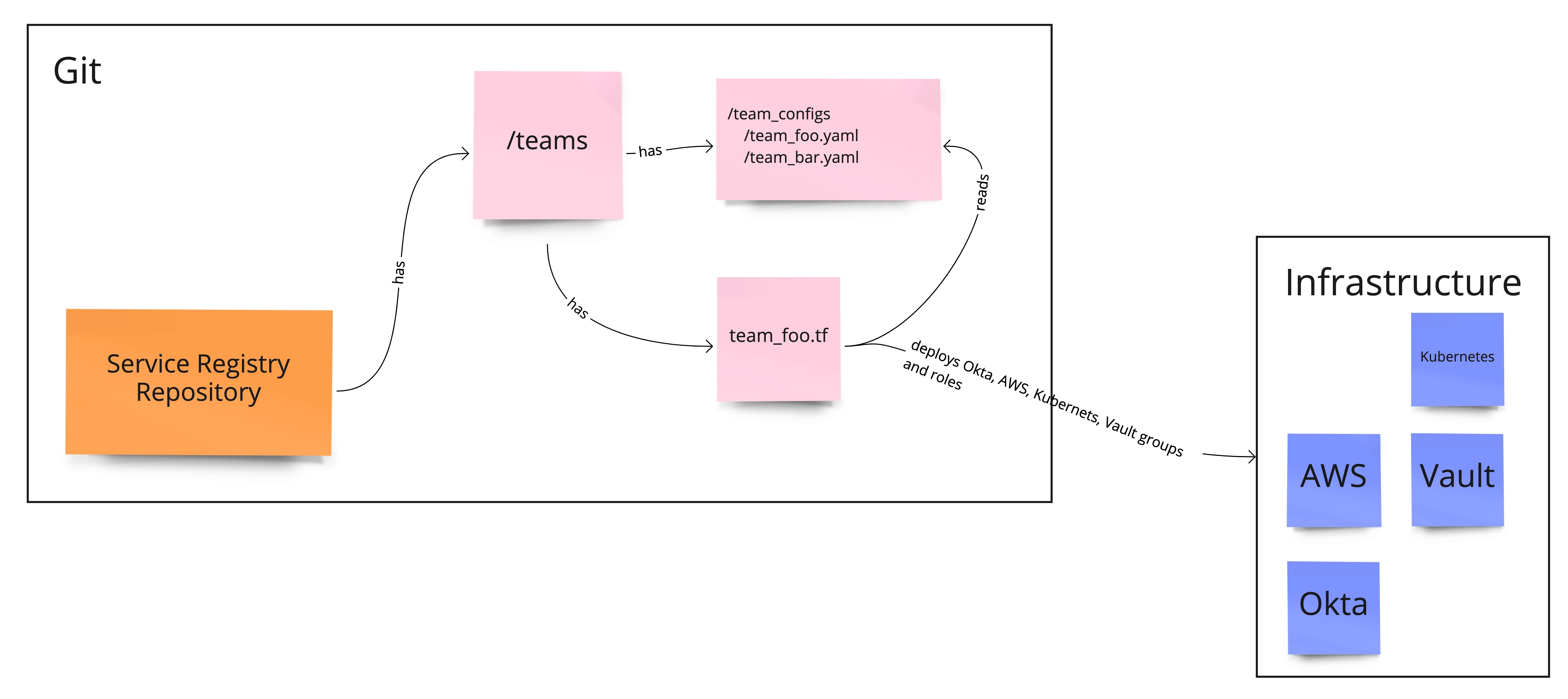
Figure 2. Teams perspective
If a team needs to create a new service, they just generate a YAML manifest with required attributes and add the service name to the list of owned services in the team manifest. If another team needs access to the service, the name of the team can just be added to the “guest” list in the manifest which will create all necessary permissions. If the ownership of a service moves to a completely different team, the DevOps team doesn’t need to touch the infrastructure anymore. The new owner puts service name in its “owner” list, removes it in the old team configuration and all permissions will automatically be assigned accordingly.
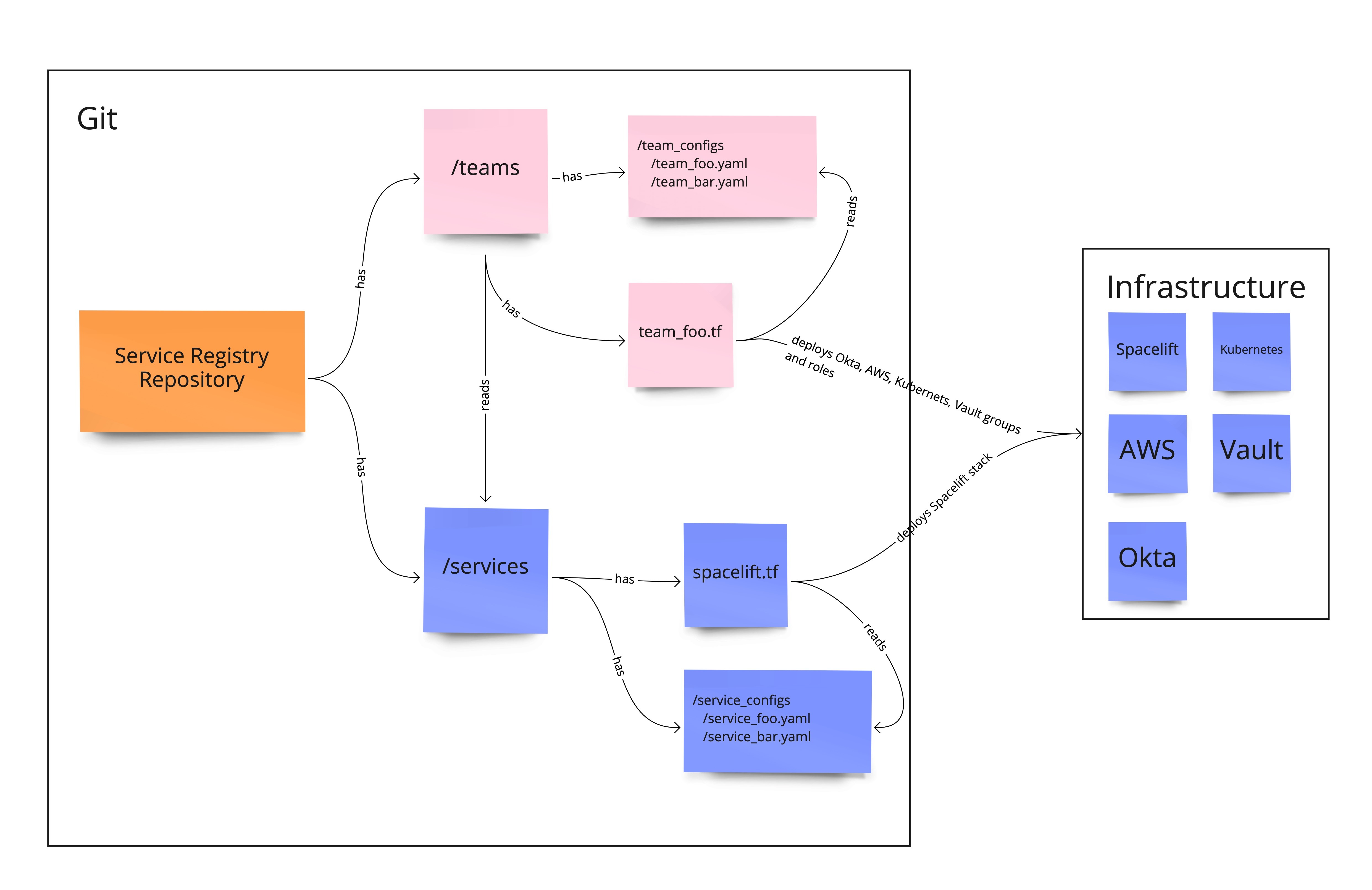
Figure 3. Services and teams integration
Infrastructure Pipelines using Spacelift
Spacelift is a CICD platform for Infrastructure-as-Code. It currently supports Terraform and Pulumi, with CloudFormation on its way. It allows defining stacks that track a repository and get triggered when a certain folder in the repository gets changed. It then plans Terraform changes and shows in UI asking for approval.
TIER uses Spacelift to execute our Terraform pipelines and to guarantee that each change to the infrastructure can be reviewed before it’s rolled out to make sure that the change is correct. But we want our teams to remain autonomous for the most part. So clearly, reviewing every change manually isn’t what we want either.
Luckily, Spacelift is built around policy-as-code idea and uses Open Policy Agent (OPA), which allows us to have automatic reviews of those plans. For example, if the plan only contains changes creating new resources, we allow and apply them automatically. On the other side, if the plan destroys resources, we ask for explicit approval. That allows developers to commit Terraform templates to the repository and keep working on their code without being distracted by extra manual steps.
Moreover, Spacelift has a Terraform provider which allows us to create Spacelift stacks per environment and per service registered in Service Registry. In other words, each time a developer creates a new service, we automatically provision staging and production stacks tracking the service repository for Terraform-related changes.
What comes next?
In this blog post, we had a look at our Service Registry concept and how it helps us together with Spacelift to enable developers to bootstrap new services faster and manage their access with ease. Are you curious to find out how we integrate Slack, Pagerduty and DataDog to the teams and services registered in Service Registry? In the upcoming blog post, our Expert Site Reliability Engineer, Alexander Hellbom, will tell you more about it!
Below you can find a video with Timur’s talk for HashiTalks.
Thanks for watching!
Please find the the archive with code example here.
{kind=link}

How analytics engineers keep data modelling efficient and clean at TIER
Open-sourcing the Dependabot - CodeArtifact sync tool
