
This post is Part 1 in a series describing our journey to FaaS with Knative
At TIER, we’ve gone through several iterations how we design and run our services. Our journey started from AWS lambda functions built on top of serverless.com. We evolved from there to a monolithic application that served our core business logic before splitting it into microservices. Recently, we wrote about how we split our legacy monolith application into smaller independently deployable microservices.
Moving to a microservices architecture allowed us to scale and improve our velocity to release features to our users. However, we started getting to feel the burden of Metcalfe’s Law, with too many microservices directly talking to each other, which prompted us to start adding event-driven, fine-grained, and self-contained functions into the mix. In this post, we’ll share our journey into the serverless (FaaS) world using Kubernetes and Knative and the lessons we learned along the way.
First things first. When you hear of serverless for the first time, it may sound like a hypothetical world where servers do not exist. Of course, the computation needs to happen somewhere, so there are still servers, but they’re abstracted away from you.
Serverless is a development paradigm that lets you deploy and invoke ephemeral functions to process data or to handle requests. Usually events trigger the execution of functions, and the hardware needed to execute these function is provisioned only for the run time of the function and de-provisioned after the code finishes executing.
For example, let’s say you could create a microservice in charge of user registration and authentication domain. The microservice could be responsible for allowing users to authenticate into the system and also allowing them to reset their passwords.
With FaaS, we could further decompose such microservice into smaller units, each handled by a function. A function may handle authentication requests; another function may also handle password reset requests. Additionally each function can be deployed and scaled independently. Furthermore, changes to business logic are then localized within a single function.
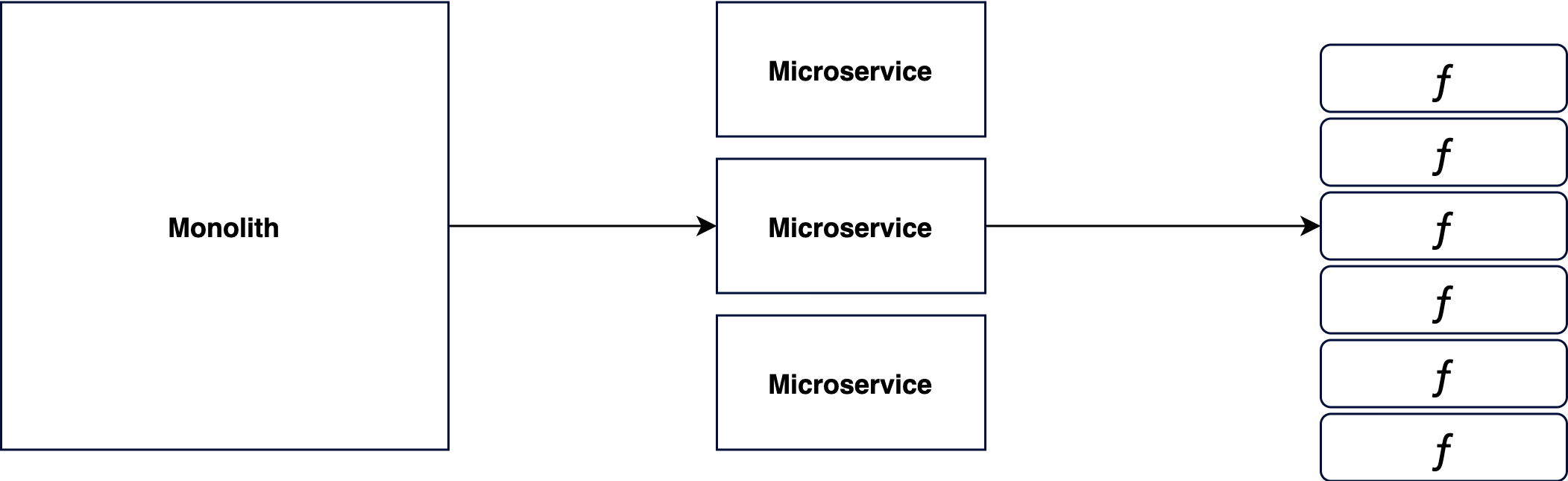
Fig 1: Decomposing microservice into self-contained, short-lived functions
Our Journey to FaaS Again (Serverless)
For a startup, technologies and architectures change rapidly, and it can be tempting to adopt them as fast as they change by migrating to the latest cool tech. Our engineering team strives to strike a balance between choosing reliable technologies and new innovative technologies. Especially, we don’t want to optimize for or solve a problem that does not impact our customers in some way.
But since we needed to decouple our microservices using an event-driven approach to keep engineering momentum with many teams, serverless appears to be a great option to remove the technical overhead for our engineers.
Our services communicate asynchronously through multiple Kafka brokers. With the abundance of events that every service could now consume, we started having more and more problems reacting to a large number of events.
In the following paragraphs, we’ll discuss some of these problems.
We often have events from multiple sources that we need to stitch together from different places to execute our business logic. A simple example is triggering a notification message based on the number of rides taken within a certain time frame through our CRM tool.
Figure 1: Reacting to events in the app
We want to go all-in into event-driven architecture, but that means we need to make it easy to create new services for handling these events. The creation of a new microservice in production still had a large configuration overhead. Service owners (product teams) often have to define their service scaling requirements, for example how much memory or CPU a service might require.
So, instead of having our software engineers monitor their CPUs to calibrate their services, we wanted an architecture that is simple and scalable by default and allows engineers to focus on business logic rather than getting lost in the infrastructure boilerplate code. We want to leverage a platform that takes care of service configuration and scaling to allow our engineers to focus more on writing code. This in turn makes room for more innovation and also lowers the barrier of entry for new engineers.
Lastly, availability, scalability, and cost optimization are critical to us. Within a service, we often see that some parts of the service require varying scaling needs. Adding a payment method may require different scaling requirements than charging for a ride. The Serverless paradigm helps us to further decompose a microservice into smaller functions that scale in response to demands.
There are many FaaS providers, in the next section we’ll explore why we picked Knative in our serverless setup.
Why We Chose Knative
Knative is an extension of the Kubernetes container orchestration platform that enables serverless workloads to run on Kubernetes clusters. It provides tools that make building, deploying, and managing containerized applications within Kubernetes simpler and feels more coherent to the engineers.
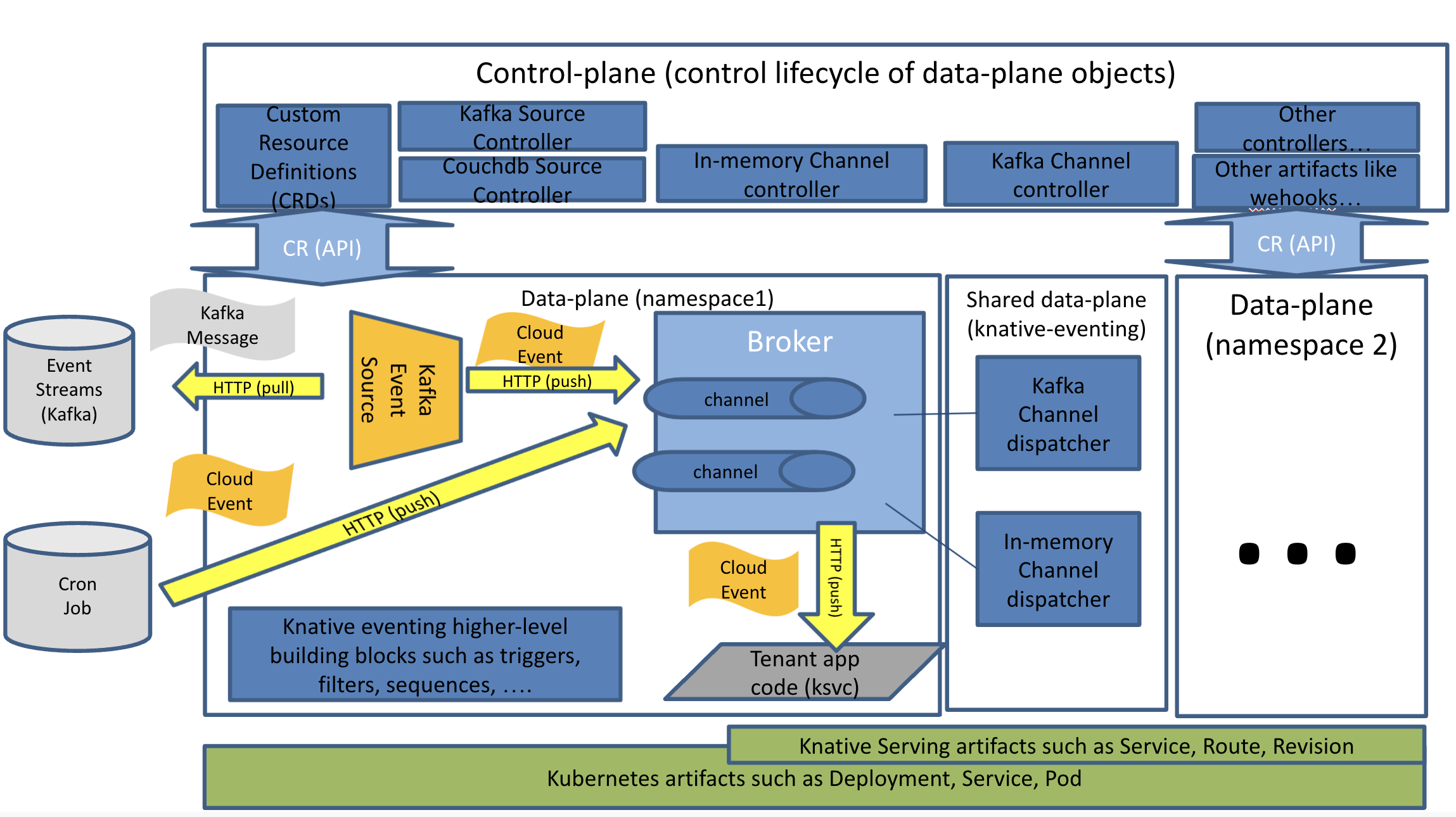
Figure 3: Knative eventing architecture diagram (source)
Knative is not the only serverless platform available in the market. There is AWS Lambda, Azure Functions, and more. Since we run our clusters on AWS, AWS Lambda could also have been an option. However, we chose Knative for multiple reasons:
- It’s native to Kubernetes where our services already run. Furthermore, it has a flatter learning curve as our engineers are already familiar with Kubernetes. This means our engineers can directly use the same Kubernetes API they’re already familiar with to also deploy serverless functions.
- Knative comes with a built-in solution to trigger functions from Kafka events. It allows us to trigger serverless functions in Knative using the built-in event system.
- Our environment is already containerized using docker in Kubernetes. Knative allows full interoperability between existing workloads and serverless functions.
- CloudEvent provides us with a common way to define events across our organization.
How FaaS helped us
Using serverless helped us to simplify our development flow and setup tremendously. Although it requires a shift in mindset, it has benefited us in many ways such as:
- Fast iteration: It allows developers to focus on business logic shifting the focus to business capabilities that functions should enable.
- Easy to test: Because functions react to HTTP events, we can easily test them without mocking other infrastructure components.
- Scaling abstracted from engineers: Engineers don’t have to define their scaling needs in advance. With Function-as-a-Service, each function scales in response to demand.
- Single source of truth: Because we leverage events, they become the single source of truth that can be modified if needed.
- Finer-grained SLOs and better observability: Rather than measuring the high-level signals from a single service, we’re able to have finer-grained observability down to the function level.
Conclusion
Because FaaS shifts complexity away from developers by abstracting configurations and other boring stuff away to allow developers to focus on what matters, it may have more overhead in the beginning when it comes to setup. However, it paid off because working with Kafka events is considerably simplified for our engineers since we have self-contained functions that respond to events, whether they are HTTP events or ones we’ve triggered through Kafka streams, enabling easy automated testing and lowering the barrier of onboarding engineers to a new codebase.
To wrap up, in this post, we’ve provided a glimpse into how we’re leveraging Knative. We believe we still have a long way to go in our journey, and there will be more learnings.
The series
- How Knative helps us to go FaaS - Part 1
- [How Knative helps us to go FaaS: our learnings - Part 2] - Coming soon!


{kind=link}