
At TIER we care about our users. One of our goals is to prevent any kind of information leak and data breach. We need to ensure that integrations we make are safe and secure, the same applies to API implementations. In this blog post we raise our concerns about public-facing APIs and ways to address them.
The Data sharing team within TIER takes care of multiple integrations and APIs, one of which is an API that implements the General Bikeshare Feed Specification (GBFS). GBFS is a standard created for sharing the micromobility system information on public APIs. In our use case, the most important feature is sharing our vehicles’ (electrical scooters, bikes and mopeds) location data.
What is the problem?
Any time you implement a public-facing API, on top of making sure it stays available and protected from overuse and abuse, the critical questions to consider are: whether you’re publishing user data and whether you’re protecting that data properly.
At first glance, the GBFS standard doesn’t have any user data, since it’s only sharing information about vehicles.
Nevertheless, if you read the standard carefully the following is noted for bike_id:
[...] MUST be rotated to a random string after each trip to protect user privacy (as of v2.0). Use of persistent vehicle IDs poses a threat to user privacy.
Generally, Bike IDs, our vehicle IDs, and all universal IDs are used to uniquely identify an entity. On subsequent requests, one may be able to match the entity’s data to their previously seen versions.
In reality, this makes vehicle IDs sensitive data, because they can be used to track users, even though data about vehicles that are rented is not published on the API.
Imagine a scenario where you want to track what your child is doing in the afternoon – are they visiting the library, or are they going out with friends?
Let’s say there are two scooters nearby: ID scooter1 and ID scooter2. After scooter2 disappears, one can search for its ID later to see the person’s location.
When working with public APIs, the data is freely available on the internet, without consideration of the usage. An organization with healthy data protection policies must ensure not to publish any sensitive data. Otherwise, it could be used for unintentional purposes.
Problem solving
How can you protect against this? As mentioned above, GBFS says the ID “MUST be rotated to a random string after each trip” and the ID “SHOULD only be rotated once per trip”. ID rotation in this context means that we retire the old ID after each trip and use a new one – a somewhat similar meaning that cryptographic key rotation has.
Possible solutions are:
- On every request, the API provides a response containing different, randomly generated IDs. Easy to implement, but it’s definitely not fulfiling the “rotated only once per trip” requirement.
- After every new vehicle location, a different ID is generated. This approach is harder to implement, but it’s still not fulfiling the “rotated only once per trip” requirement because vehicles can be moved between trips while on the street. If we publish the vehicle location alongside the ID that we generated using that same vehicle location, tracking the vehicle becomes easier for an attacker who knows this (and we want to avoid security by obscurity).
- After every trip the API response contains different IDs. This solution definitely fulfills both requirements, but depending on the solution, can be very complex.
From here on, we introduce two new terms:
- “Real IDs”: The property of each vehicle within our system. It stays the same for the lifetime of the vehicle.
- “Cloaked IDs”: The rotated, anonymized IDs we publish on our public API.
We also have our own requirement that GBFS doesn’t specify: we should be able to reverse the Cloaked IDs within our own systems. Or in other words, we should be able to tell which Real ID was used to generate every Cloaked ID.
In the rental_uris fields, we can publish deep links which are intended to be used to open the TIER app at the vehicle that you found in the feed. If we had no way to reverse the IDs, we couldn’t tell which was the actual vehicle you found in the feed.
Thus, we had three requirements we wanted our solution to fulfil:
- In pure cryptographic terms, given any Probabilistic Polynomial Time-bound adversary, they should not be able to reverse a Cloaked ID.
- After every trip, the starting scooter’s Cloaked ID should be different.
- TIER systems need to be able to tell the scooter’s Real ID based on its Cloaked ID only.
Implementation
We came up with a few simple solutions:
- If we just hash the Real vehicle ID once:
- It’s reversible if we know every scooters’ Real IDs (we just hash all of them, and find our corresponding Cloaked ID) ✅
- An attacker could build a rainbow table , which is resource consuming, but a determined attacker could eventually get our Real IDs ❌
- It’s mostly pointless since it doesn’t change after every rental, so it doesn’t avoid tracking ❌
We need to find a property that changes its value after every rental. Luckily, the vehicles use a property called lastStateChange. If a user unlocks a scooter, it goes into a rented state, and when the user locks it, it becomes active again, and lastStateChange gets updated with the current millisecond:
{
"id”: “bbbbe9e4-e2b1-4f59-81ac-40faeb09a21d”,
"lastStateChange": 1635429084156
... other vehicle properties
}
- If we create a hash of the
lastStateChangeonly, that could serve as a Cloaked ID.- Changes after every rental ✅
- The rainbow table approach still applies as the timestamps can be guessed by an attacker, but it decreases the attack surface at least ❌
- But this approach is also mostly pointless since we (or the attacker) can’t find the corresponding vehicle based only on a changing timestamp, as it doesn’t uniquely identify the vehicle ❌
- If we concatenate
lastStateChangeto the Real vehicle ID and hash this:- Changes after every rental ✅
- We can get back the Real IDs after we internally reverse them (again, hashing all our
lastStateChange+RealIdcombinations, and comparing it with the incoming one), but this is very impractical since the timestamps change unboundedly, the number of combinations is theoretically infinite ⚠️ - Still somewhat sensitive to the rainbow table approach by an attacker with a lot of resources ❌
Our Product Security Team helped to resolve this situation. They came along with some amazing insights:
- If we box the
lastStateChangein a small enough range (for this example, let’s consider 256), let’s call this our ‘salt’ for now. - Then use that number for creating a hash of the salt and the Real ID, which would be the key material:
- Reversible if we know all Real IDs (our keys): ✅
- Let’s assume 10 scooters, for each we generate the 256 possible numbers, and hash their concatenated value.
- If any matches the Cloaked ID, we found our scooter.
- Changes after every rental ✅
- Again, still sensitive to the rainbow table approach, by an attacker with a lot of resources, especially if we use a small salt range ❌
- Reversible if we know all Real IDs (our keys): ✅
Some pseudo-code to illustrate it:
const salt = lastStateChange % 256;
const cloakedId = hash(realId + salt);
Reversing:
const cloakedIdToReverse = "...";
const vehicle = vehicles.find((vehicle) => {
for (let salt = 0; salt < 256; salt++) {
if (hash(vehicle.id + salt) === externalIdToReverse) {
return true;
}
}
return false;
});
The solution looks good, but what if the attacker knows our ‘salt’ range? They can also start building a rainbow table for the using our salt range, and eventually get out real IDs. By increasing the salt range, we therefore could increase the size of a rainbow table significantly while keeping the computational overhead for the lookup relatively low on our side. However, the door for the attacker would still remain open.
We had an idea of introducing a private key, and encrypting the concatenation of the Real vehicle ID and lastStateChange timestamp, without hashing anywhere, to keep the solution simple.
The issue is that the lastStateChange is pretty guessable: it’s a value with a second accuracy, and if the attacker continuously monitors the API, it’s very easy to get the exact second when the location of the vehicle changed. Knowing the timestamp would remove all bits of entropy used for actually rotating the IDs, making our algorithm insecure.
Our last solution introduces the private key for generating a secure random number based on the lastStateChange, which solves the issue mentioned above:
- We generate a secret encryption key that can be rotated at will.
- Calculate the boxed state change.
- Encrypt it symmetrically with the private key.
- Concatenate it to the scooter ID.
- Hash them.
Using the algorithm gets us to a trapdoor function, where if you have the secret key, it significantly reduces the computational cost to reverse it. Without the key, reversing the computation becomes an NP-Hard problem, and that’s where we want the attacker to be.
We use AES-256 intentionally in CTR mode because it then works as a CSPRNG, giving us random numbers using lastStateChange as a seed.
This approach achieves all three of our objectives:
- Cloaked ID is changed after every ride ✅
- Reversible Real IDs if we know the private key (cryptographically feasible, at least) ✅
- Reversing the Cloaked ID is not feasible if you don’t have the secret key, even with a lot of resources ✅
We can occasionally change the secret key, getting a simple method of making any information the attacker has collected useless.
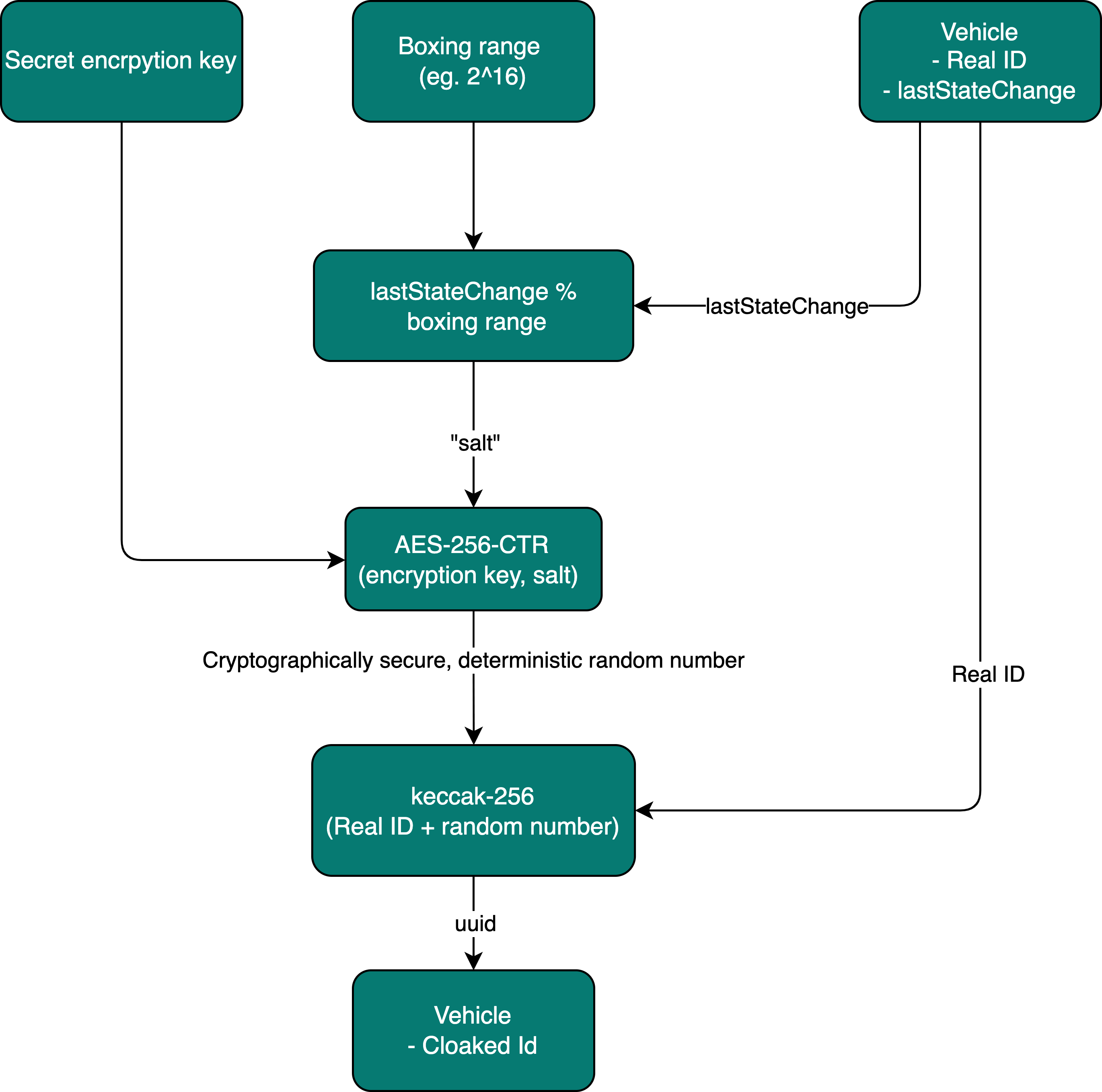
The same diagram as an equation instead:
Cloaked ID = keccak-256(Real ID + AES-256-CTR(encryption key, lastStateChange % boxing range))
It’s worth mentioning that based on how large we choose our salt range to be, the Cloaked IDs still have a chance to stay the same, before and after a rental. This chance can be very low, making it an unreliable method for following the vehicles through the API.
Considering our example, using a salt range of 256, a collision might happen once in every 65k rides. The number we actually use internally was chosen in a way that a collision could only happen once a month in any of our largest cities. This solution makes sure that our users cannot be tracked.
Reversibility
One concern is that while reversing the Cloaked IDs cryptographically is theoretically feasible for us, for many scooters and a large salt range, it becomes an extremely expensive operation:
- Assume we have
3000~=2^12vehicles V in a city and a salt S from a salt range of2^16. - We need to encrypt every value of S, then concatenate it with every value of V, and hash these. Then, we have to do
2^12 * 2^16 = 2^28comparisons we have with the Cloaked ID we received.
As a bit tongue-in-cheek calculation, let’s say we can do the range boxing, symmetric encryption, concatenation, hash and comparison in a single CPU instruction (a crazy underestimate), which let’s say happens under 1 nanosecond.
The number of calculations we have to make: 2^28 ~= 10^9. So even wildly underestimating the time it takes for a single operation to happen, reversing a single Cloaked ID takes around 1 second (10 ns * 10^9) of a full CPU core if we’re taking the cryptography route.
For the very occasional analytical query, this might be okay after some optimizations – but doing it for production traffic would be infeasible.
In this case, we should build a cache of (Cloaked ID - Real ID) pairs instead, so the reverse-lookup becomes almost instantaneous compared to calculating them. We imagine an in-memory cache to be sufficient for a first iteration, then based on measurements, we could later for example switch to Redis, if needed.
This is the perfect place to illustrate the approach the attacker needs to take: the calculations needed would be the same, except the attacker also has to guess a 256 bit AES within the range of 2^256 and try to match each key with every number in the 2^16 range. Not just that: they are going to find it hard coming up with the real vehicle IDs. It would be a fool’s errand. The only loophole with this algorithm is the collisions described above.
Wrapping up
When we started the project of GBFS, we did not expect what complexities building a public-facing API would involve. Having read the specification, we also realised that we did not consider all angles of the problem initially – vehicle IDs affecting user privacy especially came as a surprise.
We did not feel comfortable going ahead without taking as much care as we could, and we had the support of every member behind this project – as a user of our service, it makes me happy that TIER is mindful about user privacy.
Coming up with a solution for this self-contained problem was a challenging exercise, where we learned a lot of new things about cryptography and user privacy. Taking into account it is the first iteration, we would appreciate having any kind of feedback. If there are any alternatives, share your insights in the comments so we can learn and improve even more!
{kind=link}

How Knative helps us to go FaaS - Part 1
How analytics engineers keep data modelling efficient and clean at TIER
